
Computer Vision for Edge Devices: Seeing Like a Machine
Computer vision often feels like magic.

Your phone unlocks itself by looking at your face. A small camera can detect people, cars, defects on a production line. Tiny devices seem to understand the world through images.
But before talking about neural networks, models, or edge accelerators, we need to step back.
To deploy computer vision on small hardware, we must first understand a simple truth:
Machines do not see images. They process data.
This first article lays the foundation for the series. We will start from the very basics: what an image really is, how machines extract information from it, and why this matters when your final target is a constrained edge device.
What does it mean for a machine to “see”?
When humans look at an image, we instantly recognize meaning: faces, objects, motion, intent. This happens so naturally that we forget how complex the process actually is.
A machine, however, does not see objects. It does not see faces. It does not even see shapes.
A machine sees numbers.
Computer vision is the discipline of turning raw numerical data into useful information. Everything else detection, classification, tracking is built on top of that transformation.
Understanding this point is essential, especially for edge devices, where every computation has a cost.
An image is just structured data
At its core, an image is a grid.
Each cell in that grid is called a pixel, and each pixel contains one or more numbers describing intensity.
A grayscale image can be imagined as a two-dimensional table:
python
image = [
[12, 15, 18, ...],
[10, 14, 20, ...],
[...]
]Each number represents how bright that pixel is.
Color images are just an extension of the same idea. Instead of one grid, you have multiple grids stacked together typically one for red, one for green, and one for blue.
So an image is not a picture. It is a data structure with spatial meaning.
This perspective is crucial for edge computing: memory usage, data movement, and numerical precision all depend on how these grids are stored and processed.
Resolution and precision
Two properties of images matter a lot when working on small hardware:
Resolution (how many pixels)
Precision (how many bits per pixel)
Higher resolution means more data. Higher precision means more memory and more computation.
On powerful servers, this often goes unnoticed. On edge devices, it is the difference between a system that runs smoothly and one that fails to deploy.
One of the recurring themes in this series will be learning how to ask:
“Do I really need this much information?”
Because in computer vision, more data is not always better.
Locality: vision emerges from neighborhoods
One of the most important ideas in computer vision is locality.
Most useful visual information comes from comparing a pixel with its neighbors.
Edges appear where intensity changes abruptly. Textures emerge from repeating local patterns. Motion is detected by observing how local regions change over time.
Conceptually, many vision algorithms follow this pattern:
bash
for each pixel:
compare with nearby pixelsThis simple idea explains why computer vision scales well and why it can be optimized for edge devices.
Local operations can often be computed efficiently, reused, or approximated. They also map naturally to specialized hardware and low-power processing.
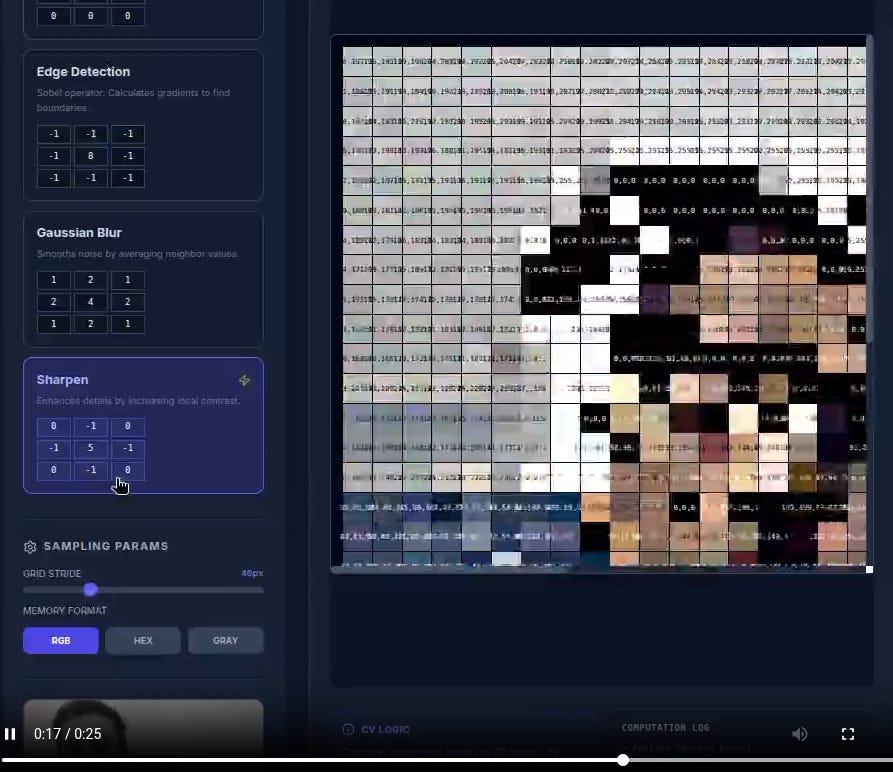
Computer vision application. How a computer sees an image.
Computer vision as transformation, not intelligence
It is tempting to think of computer vision as a form of artificial intelligence that understands images.
In practice, it is better described as a pipeline of transformations.
A typical vision system looks like this:
Capture an image from a sensor
Preprocess it (resize, normalize, filter)
Extract relevant features or representations
Interpret those representations
Produce an output or decision
Each step transforms data into a more useful form.
For edge devices, this pipeline mindset is essential. It allows you to:
Move computation closer to the sensor
Remove unnecessary steps
Decide what must run locally and what can run elsewhere
Efficiency comes from understanding where value is created along the pipeline.
Before deep learning, vision already worked
Modern computer vision is often associated exclusively with deep learning.
But long before neural networks became popular, systems were already detecting edges, tracking motion, recognizing shapes, and measuring distances often in real time and on very limited hardware.
Why does this matter today?
Because edge devices force us to revisit the same constraints:
Limited memory
Limited power
Real-time requirements
Classic computer vision techniques are not obsolete. In many edge scenarios, they are still the most efficient solution or an essential pre-processing step before a learned model.
Why edge devices change the rules
Running computer vision on the edge is not just about moving models closer to the camera.
It introduces new priorities:
Latency: decisions must be immediate
Power: every operation consumes energy
Memory: models must fit in constrained environments
Reliability: connectivity may be unavailable
Privacy: raw images often cannot leave the device
These constraints force us to think carefully about what we compute and why.
Understanding images as data, and vision as transformation, is the first step toward making the right trade-offs.
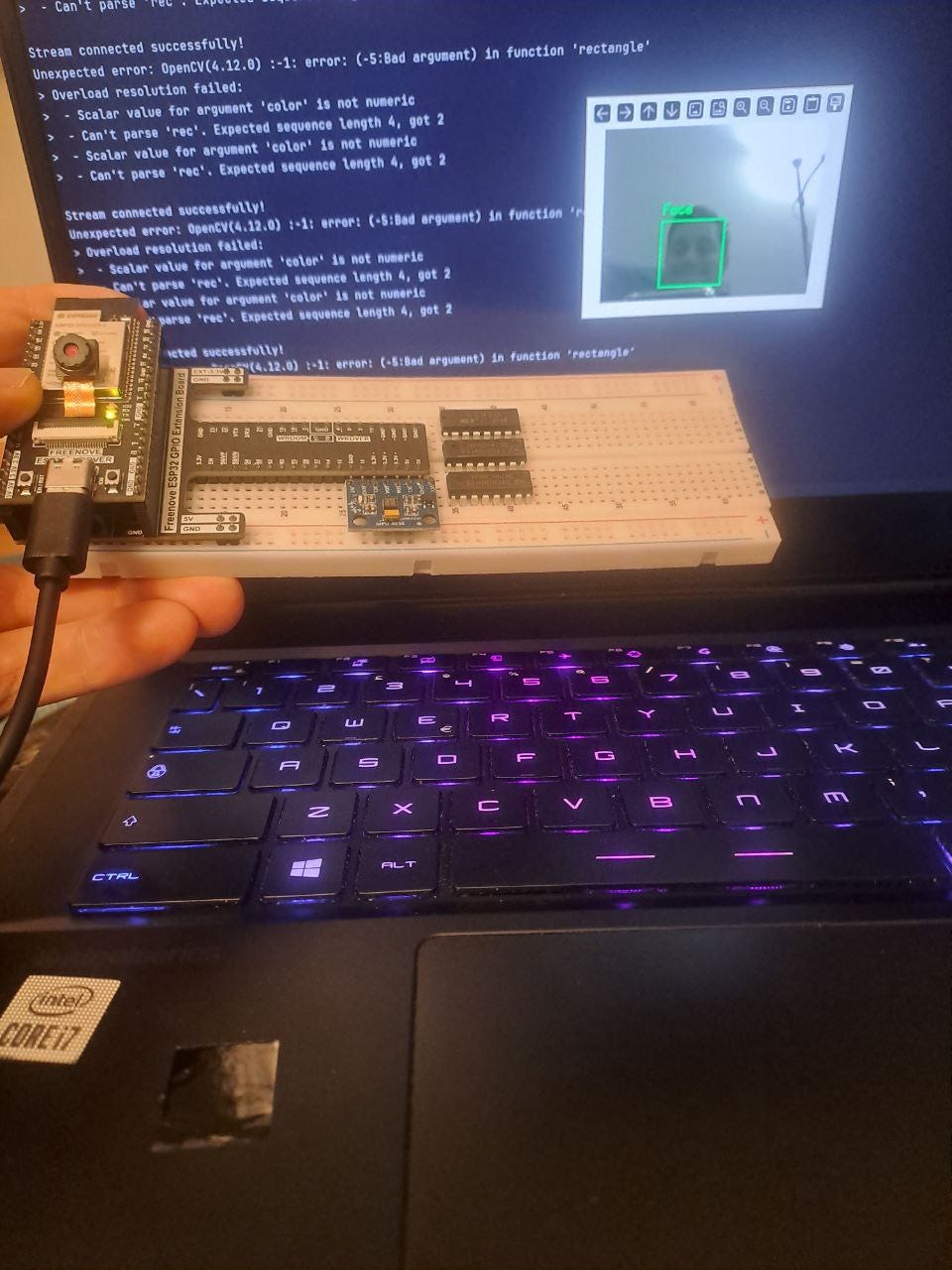
ESP32 stream video application example
Looking ahead
In this first article, we stripped computer vision down to its essentials:
Images are structured numerical data
Visual information emerges from local patterns
Vision systems are pipelines, not black boxes
In the next episode, we will explore how these basic ideas evolved into modern computer vision approaches and how deep learning fits into the picture, especially when your final target is a small, resource-constrained device.
Computer vision on the edge is not about making machines see like humans.
It is about making them see just enough.
Code for the computer visions projects:
https://github.com/orgs/computer-vision-with-marco/repositories